On March 12, 2026, Stanford’s Scaling Intelligence Lab dropped something the AI agent ecosystem has been quietly missing: a framework built around the uncomfortable truth that “personal AI” running entirely on someone else’s servers isn’t actually personal. OpenJarvis isn’t just another agent framework — it’s Stanford’s answer to a specific research finding that local models can already handle 88.7% of single-turn queries at interactive latencies, and the software stack to prove it has been the blocker, not the hardware. The models are ready. The hardware is ready. Now there’s a stack.
Rating: 8.4/10 ⭐⭐⭐⭐
What Is OpenJarvis?
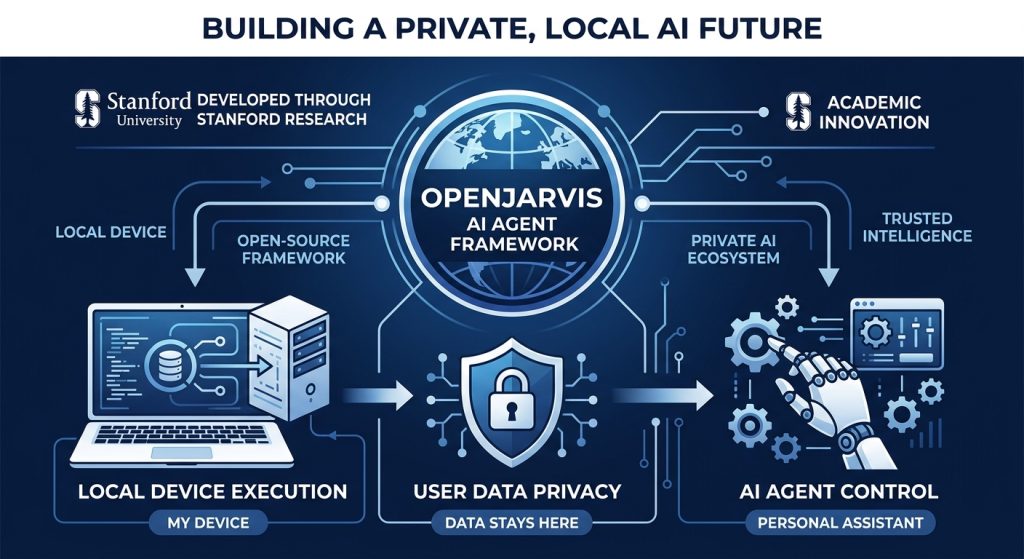
OpenJarvis is an open-source framework for building personal AI agents that run entirely on-device. It comes out of Stanford’s Scaling Intelligence Lab and Hazy Research group, released under Apache 2.0 on March 12, 2026. The lead researchers are Jon Saad-Falcon and Avanika Narayan, with Stanford legends Christopher Ré and Azalia Mirhoseini in the author list.
One-line differentiator: OpenJarvis is the PyTorch of local AI agents — a shared, opinionated stack that replaces the chaos of bespoke local AI setups with five composable primitives anyone can build on, benchmark, and optimize independently.
Unlike LangChain, CrewAI, or AutoGen — which assume cloud inference as the default — OpenJarvis treats local execution as the default and cloud as an optional fallback. Everything: tools, memory, learning, benchmarking, runs on your hardware. No data leaves unless you choose it. GitHub | Official Docs
The Story: Why Stanford Built This (And Why the Timing Is Right)
The Stanford team didn’t build OpenJarvis in a vacuum. It’s the follow-up software layer to a research project called Intelligence Per Watt, which measured how much of real-world AI query load local hardware can actually handle. The headline number: 88.7% of single-turn chat and reasoning queries can be accurately served by local models at interactive speeds. Intelligence efficiency improved 5.3× from 2023 to 2025.
That research created an awkward gap. If local models and consumer hardware are already practical for most AI workloads, why is every “personal AI” assistant still routing your calendar, messages, notes, and documents through a data center you don’t control? The Stanford team’s diagnosis: it’s not model capability that’s holding local AI back. It’s the software stack. Nobody has built the equivalent of PyTorch for local AI agents — a shared set of abstractions that replaces bespoke, brittle integrations.
OpenJarvis is their answer to that gap. The framing is deliberate: they compare it to the 1970s-80s shift from mainframes to personal computers. Not because PCs were more powerful, but because they became efficient enough for what people actually needed. The same inflection is happening with AI — and OpenJarvis is betting on being the framework that makes it real.
Benchmark Performance
OpenJarvis is built around its own efficiency-first benchmarking via the jarvis bench command, which tracks latency, throughput, and energy per query across NVIDIA (NVML), AMD, and Apple Silicon (powermetrics) at 50ms sampling intervals. The key Stanford research data point driving the framework:
| Metric | OpenJarvis (Local) | Typical Cloud Agent | Notes |
|---|---|---|---|
| Query coverage (local vs cloud quality) | 88.7% of queries | 100% (requires cloud) | Source: Intelligence Per Watt study (Stanford, 2025) |
| Efficiency improvement (2023–2025) | 5.3× gain | Flat (cloud cost scales linearly) | Local hardware efficiency trajectory |
| Latency (interactive threshold) | ✅ Met on consumer hardware | ✅ Met (network-dependent) | Comparable for most use cases |
| Data privacy | 100% local by default | ❌ Data leaves device | Hard architectural difference |
| Recurring API cost | $0 (after hardware) | $20–$200+/mo | Depends on usage volume |
| Benchmarks tracked | 30+ built-in | Framework-dependent | OpenJarvis evaluation harness |
The efficiency and privacy numbers are the benchmark story here. OpenJarvis isn’t claiming its agents perform better on task quality than GPT-4o or Claude 3.7 — it’s claiming the model capability gap has closed enough that you should stop defaulting to cloud, and start accounting for energy, cost, and data sovereignty as real engineering constraints.
Comparison against major competing frameworks on key dimensions:
| Metric | OpenJarvis | LangChain Agents | CrewAI | Microsoft AutoGen |
|---|---|---|---|---|
| Local-first execution | ✅ Default | ⚠️ Optional | ⚠️ Optional | ⚠️ Optional |
| Energy/cost telemetry | ✅ Built-in (50ms sampling) | ❌ None | ❌ None | ❌ None |
| On-device learning loop | ✅ SFT, GRPO, DPO, DSPy | ❌ None | ❌ None | ❌ None |
| Inference backend flexibility | 10+ backends | Multiple (cloud-first) | Limited | Multiple |
| Hardware auto-detection | ✅ jarvis init | ❌ | ❌ | ❌ |
| Offline operation | ✅ Full functionality | ❌ Cloud required | ❌ Cloud required | ⚠️ Partial |
| MCP support | ✅ Native | ✅ Via integration | ⚠️ Limited | ✅ Via integration |
Sources: Official documentation for each framework, March 2026. Cloud agent latency/cost assumptions based on OpenAI API pricing.
Pricing
OpenJarvis is free and open-source under Apache 2.0. The actual cost conversation is about what you’re comparing it against.
| Option | Monthly Cost | Data Privacy | Offline? | Notes |
|---|---|---|---|---|
| OpenJarvis | $0 (Apache 2.0) | ✅ 100% local | ✅ Yes | Requires local GPU/CPU hardware |
| ChatGPT Plus | $20/mo | ❌ OpenAI servers | ❌ No | GPT-4o, fixed model |
| Claude Pro | $20/mo | ❌ Anthropic servers | ❌ No | Claude 3.7 Sonnet |
| LangChain + OpenAI API | $20–$200+ (usage) | ❌ Cloud API | ❌ No | Cost scales with tokens |
| CrewAI (Enterprise) | Contact sales | ⚠️ Depends on config | ❌ No | Managed service tier |
| Microsoft AutoGen | $0 (open-source) | ⚠️ Needs cloud model | ⚠️ Partial | Still needs OpenAI/Azure LLM costs |
The hidden cost of “free” frameworks like LangChain or AutoGen is that they still pipe inference through paid cloud APIs. OpenJarvis is the first major framework where the whole stack can run at $0/month marginal cost on hardware you already own. At scale (thousands of queries/day for automation), that becomes a significant infrastructure cost difference.
Key Features
1. Five-Primitive Architecture
OpenJarvis organizes everything around five composable layers: Intelligence (model), Engine (inference runtime), Agents (behavior), Tools & Memory (grounding), and Learning (adaptation). Each primitive has a clean interface and can be swapped, benchmarked, or replaced independently. This is the design that makes OpenJarvis different from LangChain’s sprawling component library — it’s opinionated about what the layers are, which means you can actually study and optimize them in isolation. The limitation: that opinionation means less flexibility if your architecture doesn’t map to these five boxes.
2. Hardware-Aware Inference Engine
jarvis init detects your hardware — GPU vendor, VRAM, Apple Silicon vs x86 — and recommends the optimal inference backend from 10+ supported runtimes: Ollama, vLLM, SGLang, llama.cpp, MLX, Exo, LiteLLM, and cloud fallbacks. jarvis doctor monitors and maintains that setup. This removes the single most painful part of local AI setup: figuring out which backend actually works for your hardware and model size. The limitation: recommendations are only as good as the hardware detection, and edge cases (unusual GPU configs, shared VRAM setups) may require manual tuning.
3. On-Device Learning Loop
This is the feature that separates OpenJarvis from every other agent framework. Interaction traces stay on-device and feed a closed-loop optimization pipeline across four layers: model weights (SFT, GRPO, DPO), prompts (DSPy optimization), agent logic (GEPA), and inference engine (quantization selection, batch scheduling). Your agent literally gets better at your specific workflows over time, using your own data, without any of it leaving your machine. The limitation: running SFT or GRPO locally requires meaningful GPU memory — this isn’t a MacBook Air feature. Budget at minimum a 16GB VRAM GPU for training loops.
4. Energy and Cost Telemetry
Built-in hardware telemetry profiles GPU power draw via NVML (NVIDIA), AMD GPU drivers, and Apple’s powermetrics at 50ms intervals. jarvis bench benchmarks latency, throughput, and energy per query. The built-in dashboard visualizes cost savings vs cloud alternatives in real time. This is the feature that turns efficiency from a vague goal into something you can actually measure and optimize. No other mainstream agent framework has this. The limitation: cost comparisons assume you’re comparing to cloud APIs — the savings calculation breaks down if you’re running on expensive cloud GPUs instead of consumer hardware.
5. OpenAI-Compatible API Server
jarvis serve starts a FastAPI server with Server-Sent Events (SSE) streaming that’s a drop-in replacement for OpenAI clients. If you have existing code hitting the OpenAI API, you can point it at your local OpenJarvis server and nothing else changes. That’s a migration path that removes the usual “but I’d have to rewrite everything” objection to going local. The limitation: OpenAI-compatible doesn’t mean identical — function calling schemas and some advanced API features may require adaptation.
Who Is It For / Who Should Look Elsewhere
Use OpenJarvis if you:
- Handle sensitive data (legal, medical, financial, personal files) and need hard guarantees that inference never touches external servers
- Run high-volume automation workflows where cloud API costs are a real line item ($50+/month on LLM tokens)
- Want to study or contribute to local AI research — the 30+ benchmark harness and composable architecture are genuinely research-grade infrastructure
- Are a developer building privacy-first AI applications who wants a production-ready local inference stack instead of rolling your own
- Have capable hardware (16GB+ VRAM, modern Apple Silicon) and want to fully leverage it instead of paying for cloud
- Want cron-based AI automation (morning briefings, email triage, research digests) running 24/7 without recurring API costs or data exposure
Look elsewhere if you:
- Need best-in-class task performance on complex reasoning — GPT-4o and Claude 3.7 still outperform any local model for hard tasks; OpenJarvis solves cost and privacy, not frontier model capability
- Are a non-technical user looking for a plug-and-play AI assistant — this is a framework for builders, not end-users
- Need a mature, production-tested agent ecosystem with enterprise support — OpenJarvis is 6 days old at time of writing; LangChain has years of battle testing
- Are running on low-end hardware (CPU-only, <8GB RAM) — local inference is technically possible but painfully slow for most useful models
OpenJarvis vs. The Competition
| Feature | OpenJarvis | LangChain Agents | CrewAI | Microsoft AutoGen |
|---|---|---|---|---|
| Primary model | Local-first (cloud optional) | Cloud-first (local optional) | Cloud-first | Cloud-first (local partial) |
| Price | $0 (Apache 2.0) | $0 + LLM API costs | $0 (OSS) / Enterprise | $0 (MIT) + LLM API costs |
| On-device learning | ✅ Yes (SFT, GRPO, DPO, DSPy) | ❌ No | ❌ No | ❌ No |
| Energy telemetry | ✅ Built-in | ❌ None | ❌ None | ❌ None |
| Hardware auto-detect | ✅ jarvis init | ❌ | ❌ | ❌ |
| Offline operation | ✅ Full | ❌ Requires cloud LLM | ❌ Requires cloud LLM | ⚠️ Partial |
| Inference backends | 10+ (Ollama, vLLM, llama.cpp, MLX, Exo…) | Multiple (via integrations) | Few (cloud-focused) | Multiple |
| MCP support | ✅ Native | ✅ Via integration | ⚠️ Limited | ✅ Via integration |
| Multi-agent | ✅ Orchestrator + Operative roles | ✅ LangGraph | ✅ Core feature | ✅ Core feature |
| Maturity | v0.1.0 (March 2026) | 3+ years, production-grade | 2+ years, production-grade | 2+ years, production-grade |
| Backing | Stanford SAIL / Apache 2.0 | LangChain Inc. / MIT | CrewAI Inc. / MIT | Microsoft Research / MIT |
| Best for | Privacy-first, local automation | General LLM apps, RAG | Multi-agent workflows | Complex multi-agent (enterprise) |
Controversy: What They Don’t Advertise
1. The 88.7% Number Has Fine Print
Stanford’s headline stat — local models handle 88.7% of queries — comes from single-turn chat and reasoning benchmarks. Multi-turn, complex agentic workflows with tool use are harder. The gap between local Qwen/Llama models and GPT-4o/Claude 3.7 on complex coding, multi-step reasoning, and nuanced instruction following is real and non-trivial. OpenJarvis doesn’t close that gap; it argues the gap is acceptable for most personal AI use cases. That’s probably true for email triage and research digests. It’s less true for “build me a full-stack app” or complex legal document analysis.
2. v0.1.0 Is a Research Release, Not a Production Release
The framework is 6 days old. The desktop app has a known macOS workaround (you need to run xattr -cr /Applications/OpenJarvis.app if it shows as “damaged”). The learning loop (SFT, GRPO, DPO on-device) is described as operational, but there are no published benchmarks yet showing how much local fine-tuning actually improves task performance on real workloads. “Research platform” and “production foundation” are both in the mission statement — they’re pulling in opposite directions at v0.1.0.
3. Hardware Requirements Are Not Trivial
OpenJarvis works on “consumer hardware” — but that phrase is doing heavy lifting. Running a useful 7B parameter model with fast inference needs at minimum 8–16GB VRAM. The on-device learning loop (SFT/GRPO) requires more. Most laptop users are going to hit walls quickly. Apple Silicon M3/M4 chips with unified memory are the sweet spot for consumer local AI, but that’s a $1,200+ entry point. Windows GPU setups vary wildly in performance. The “run it on your MacBook” story is real, the “run it on your old laptop” story is not.
4. The Ecosystem Is Day One
LangChain has three years of community integrations, tutorials, StackOverflow answers, and battle-tested patterns for production edge cases. OpenJarvis has a Discord server and a research blog post. For developers evaluating this for serious production use: the framework design is genuinely excellent, but the ecosystem that makes a framework trustworthy for production — documentation edge cases, community debugging patterns, known-good configurations — will take time to build. Adopting at v0.1.0 means being an early builder, with all the friction that entails.
5. “Optional Cloud” Still Means You’ll Use Cloud Sometimes
The framing is “cloud as optional fallback,” but for the hardest 11.3% of queries (per the Intelligence Per Watt research), local models fall short. If your workflows hit that gap regularly, you’re still running hybrid — which means you still need API keys, you still have some data exposure, and the cost savings are partial. OpenJarvis doesn’t make this a secret, but the marketing framing emphasizes the 88.7% headline rather than the 11.3% asterisk.
Pros and Cons
Pros
- Genuine local-first architecture — not a checkbox, not a marketing claim. Offline by default, cloud by choice. Hard to overstate how rare this is in a production-grade agent framework.
- Stanford pedigree and research depth — Christopher Ré (co-creator of Snorkel, advisor to OpenAI) and Azalia Mirhoseini (former Google Brain) give this real credibility. This isn’t a weekend project.
- On-device learning loop — no competing framework offers this. Your agent improves on your data, on your hardware. That’s genuinely novel at this level of accessibility.
- Energy and cost telemetry as first-class metrics — forces efficiency into the engineering conversation instead of treating it as an afterthought. 50ms sampling granularity is serious instrumentation.
- OpenAI-compatible API server —
jarvis serveas a drop-in replacement lowers the adoption barrier for developers with existing OpenAI integrations significantly. - Apache 2.0 license — permissive for commercial use. No GPL surprise when you ship a product built on it.
- 30+ benchmark evaluation harness — genuinely useful for research teams who want reproducible comparisons, not just anecdotal benchmarks.
Cons
- v0.1.0 maturity — there are rough edges. The macOS app workaround on day one is a minor sign of a framework that shipped fast. Expect to encounter undocumented edge cases.
- Hardware ceiling — meaningful local inference requires real GPU resources. 8GB VRAM minimum for useful models; 16GB+ for the learning loop. Not everyone’s hardware qualifies.
- Ecosystem is bare — compared to LangChain’s library of integrations, community examples, and production war stories, OpenJarvis has a long road ahead. The primitives are elegant; the community knowledge base doesn’t exist yet.
- No published learning loop benchmarks — the on-device SFT/GRPO/DPO pipeline is a compelling claim. Hard proof that it meaningfully improves task quality on personal workloads would be more convincing than the current description.
- Complex task quality gap — local models are good enough for 88.7% of queries; the remaining 11.3% matters if your workflows hit hard reasoning tasks. OpenJarvis doesn’t fix frontier model capability.
Getting Started with OpenJarvis
Setup is faster than most agent frameworks because jarvis init handles hardware detection and configuration automatically.
Step 1: Install
# Option A: pip (Python SDK + CLI)
pip install openjarvis
# Option B: Full stack (browser dashboard + backend)
git clone https://github.com/open-jarvis/OpenJarvis.git
cd OpenJarvis
./scripts/quickstart.sh # installs deps, starts Ollama, launches UI at localhost:5173Step 2: Initialize and verify hardware
jarvis init # auto-detects your GPU, recommends engine + model
jarvis doctor # verifies the setup is healthyOn first run, jarvis init will recommend an inference backend (Ollama for most users, vLLM or llama.cpp for power users) and a model matched to your available VRAM. Let it pick unless you have a specific reason not to.
Step 3: Run your first query
jarvis ask "Summarize the last 5 emails in my inbox"
# With specific agent type and tools:
jarvis ask --agent orchestrator --tools calculator,web_search "What's 15% of $847 and who won the 2026 NBA championship?"Step 4: Index your local documents for RAG
jarvis memory index ./documents/
jarvis memory search "quarterly budget projections"This builds a local semantic index over your files. Nothing leaves your machine. Once indexed, any agent query can retrieve from your local knowledge base automatically.
Step 5: Set up cron automation (the killer feature)
# Start the API server (OpenAI-compatible, SSE streaming)
jarvis serve --port 8000
# Then schedule agents via cron or your scheduler of choice:
# "Every morning at 7am: pull calendar, check email, generate briefing"This is where OpenJarvis earns its keep vs. cloud alternatives. Cron-based AI automation running 24/7 on your hardware, no API bills, no data exposure. Point it at your messaging platforms (Telegram, iMessage, WhatsApp), connect MCP tools, and you have a local AI stack that works while you sleep.
Desktop app users: download from Windows / macOS / Linux (DEB). macOS users: run xattr -cr /Applications/OpenJarvis.app if you see a “damaged app” warning.
Final Verdict
OpenJarvis is the most architecturally serious local-first AI agent framework released to date, and it comes with Stanford’s credibility and a research pedigree that means it won’t get quietly abandoned. The five-primitive design is genuinely clean. The energy telemetry is genuinely novel. The on-device learning loop is genuinely ambitious in a way no competing framework has attempted.
The honest caveat: it’s v0.1.0, released six days ago. The ecosystem doesn’t exist yet. If you’re evaluating this for a production workload that needs battle-tested reliability, the answer right now is “watch closely, contribute early, deploy later.” If you’re a developer who wants to be building on the right foundation before it hits critical mass — the way early adopters of PyTorch were before TensorFlow dominance shifted — the answer is install it today.
Who should install it today: Developers building privacy-first AI applications, researchers studying local AI efficiency, technical users with capable hardware who want to stop paying cloud API bills for automation workflows.
Who should wait: Enterprise teams needing production stability, non-technical users, anyone running hardware below 8GB VRAM.
Bottom line: OpenJarvis is an 8.4/10. It’s not there yet on ecosystem maturity — but the architecture is right, the team is right, and the timing is right. This one’s worth watching closely.
What is OpenJarvis?
OpenJarvis is an open-source framework from Stanford’s Scaling Intelligence Lab for building personal AI agents that run entirely on-device. Released March 12, 2026 under Apache 2.0, it provides five composable primitives (Intelligence, Engine, Agents, Tools & Memory, Learning) for building local-first AI systems where cloud APIs are optional rather than required.
Is OpenJarvis free?
Yes. OpenJarvis is completely free and open-source under the Apache 2.0 license, which permits commercial use. There are no subscription fees, API costs, or per-query charges — your inference runs on your own hardware at $0 marginal cost.
How does OpenJarvis compare to LangChain?
LangChain is a cloud-first framework that supports local models as an option. OpenJarvis is a local-first framework that supports cloud as an optional fallback. OpenJarvis also adds features LangChain lacks: hardware-aware inference setup (jarvis init), built-in energy and cost telemetry, and an on-device learning loop. LangChain has a much more mature ecosystem and community. OpenJarvis has the better architecture for privacy-first, local deployment.
What hardware do you need to run OpenJarvis?
Minimum practical setup: 8GB VRAM (NVIDIA or AMD GPU) or Apple Silicon M2/M3/M4 with 16GB unified memory. CPU-only setups work but are slow for anything beyond tiny models. For the on-device learning loop (SFT, GRPO), 16GB+ VRAM is recommended. The jarvis init command auto-detects your hardware and recommends the best configuration.
Can OpenJarvis work completely offline?
Yes. All core functionality — inference, memory indexing, agent execution, tool use, and the learning loop — works without a network connection. Cloud APIs (OpenAI, Anthropic, Google) are supported as optional backends, but the framework is designed to operate fully offline by default.
Who made OpenJarvis?
OpenJarvis was developed at Stanford’s Hazy Research lab and Scaling Intelligence Lab (SAIL). The lead authors are Jon Saad-Falcon and Avanika Narayan. The author list includes Christopher Ré (co-creator of Snorkel) and Azalia Mirhoseini (former Google Brain). It is part of the Intelligence Per Watt research initiative studying on-device AI efficiency.
Is OpenJarvis better than CrewAI?
For privacy-first, local deployment: yes, OpenJarvis is the better architecture. For production multi-agent workflows where you’re comfortable with cloud models: CrewAI is more mature and battle-tested. OpenJarvis has unique advantages CrewAI doesn’t offer: full offline operation, on-device learning, energy telemetry, and hardware auto-configuration. The tradeoff is ecosystem maturity — OpenJarvis launched March 2026, CrewAI has years of community knowledge.
What models does OpenJarvis support?
OpenJarvis supports any model that runs on its supported inference backends: Ollama, vLLM, SGLang, llama.cpp, MLX, Exo, LiteLLM, and more. This includes Qwen, Llama, Gemma, Granite, GLM, and other open model families. Cloud models (OpenAI GPT-4o, Anthropic Claude, Google Gemini) are also supported as optional backends via API.
What is the OpenJarvis learning loop?
The OpenJarvis learning loop uses your local interaction traces to improve the system over time — entirely on-device. It supports optimization across four layers: model weights (SFT, GRPO, DPO fine-tuning), prompts (DSPy optimization), agent logic (GEPA), and inference engine (quantization, batch scheduling). This is the only mainstream agent framework with an on-device closed-loop improvement pipeline.
Is OpenJarvis worth using in 2026?
For developers building privacy-first AI applications or researchers studying local AI: yes, absolutely worth installing and experimenting with today. For production deployments requiring enterprise-grade stability and community support: wait for v0.2+ and a more mature ecosystem. The architecture and research backing are strong — this is the right foundation for local-first AI. Rating: 8.4/10.